Caching data from the database closer to the application can greatly improve performance. However, before you start implementing cache at the application level, it’s important to ask yourself many different questions in order to make the right design decisions and ultimately get things right.
Does the application really need a cache?
I think this is the main question to ask yourself before you start implementing a cache, because the cache will complicate the design of your application.
A negative answer to the question “Does the application really need a cache?” can save a lot of development and maintenance effort because you don’t have to deal with cache invalidation, cache eviction policies, cache misses, bugs related to data inconsistency and other problems that a cache can bring to a system.
So, how do you know if you really need the cache or not? You can start with just these questions:
- Do I really need to improve application performance? What are the project’s NFRs (Non-functional requirements) now? Are the customers not satisfied with the performance, or do I just want to make the system faster for no business need?
- Can the performance be improved without implementing a cache? Can I run SQL Profiler or Query Execution Plan Analyzer and optimize queries, create missing indexes, reduce resource contention/blocking, denormalize the data etc.?
- Can other cache levels besides the application level cache (SQL Server cache, CDN, browser cache etc.) solve current performance issues?
- Can I find other bottlenecks in the application that are not related to the database? A lot of allocations to the managed heap, lack of parallelism, linear search across large collections, etc. Is the app free from it now?
It is probably possible to ask more questions related to your specific project to understand if a cache is really needed. Estimating cache needs is important to avoid over-complicating an application design.
In-memory cache or remote cache?
In-memory cache means that the data is cached in the web service’s local memory. Remote cache means that the data is cached on a remote server such as Redis or Memcached that the web service communicates with.
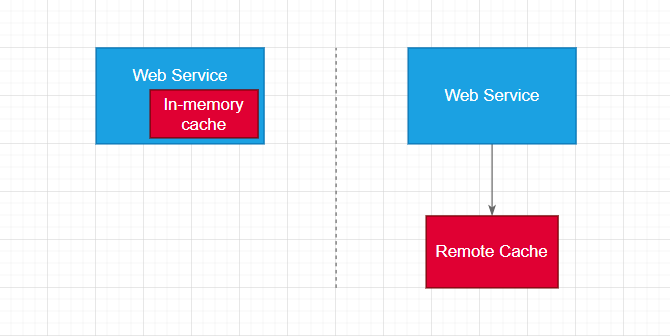
Remote cache is usually used when:
- Several different web services need to read data from the cache. In this case, the responsibility for caching data should be delegated to a separate component — the remote cache server.
- Several instances/nodes of the same web service (e.g. autoscaling) need to access data in a cache. If the same data is cached by each node in its local memory, it will be more difficult to invalidate the cache for all nodes.
- Gigabytes of data need to be cached. Storing large data in memory of a web service can slow it down due to high memory consumption, out-of-memory issues, frequent garbage collections, etc.
- The remote cache server is already configured and used in the project for things like session storage, distributed locking, streaming, etc. Start using a remote cache server for one extra duty — caching data can be a quick and easy task (but be careful and weigh the pros and cons first).
In-memory cache is usually used when:
- There is a single web service with a single node responsible for populating and reading cached data, invalidating the cache, and updating the database.
- The performance is crucial for the web service. Caching data on a remote cache server will require the web service to make regular network calls, which can take a couple of hundred milliseconds on average. Reading data from local memory is much faster.
- When different web services or multiple nodes of the same web service need to cache static data (data that never changes), they can simply use their own local memory. Each web service can simply load the copy of static data on startup and cache it in memory indefinitely.
- Reading the cache data from the remote cache server by many nodes of a web service can become a bottleneck under high load. In this case, additional caching of data in the memory of each node can significantly reduce the number of network calls to the remote cache server and eliminate the bottleneck.
What caching pattern to implement?
There are few caching patterns to choose from depending on their pros & cons and the business needs of an application.
Cache-aside Pattern

The application itself acts as an mediator for the cache layer or cache server and data source. The pattern works well when the same data is requested many times and updates to this data are rare (read-heavy workload). Also, with Cache-aside, an application can only cache what needs to be cached, but to get rarely used data, the application can always query the database directly.
The downside of the pattern is that it’s easy to get a data mismatch between the cache and the data source when you forget to invalidate the cache after updating the data in the data source, forget to set the TTL for the cache item or race conditions occur during updating the data in the database and invalidating the cache.
Read-through Cache Pattern
The pattern is very similar to Cache-aside, but the difference is that the application always reads the data from the cache layer or cache server. The cache layer or server is responsible for reading data from the database and caching it in case of a cache miss, or simply returning cached data in case of a cache hit.
The pattern is usually combined with Write-through or Write-behind patterns to support database updates.
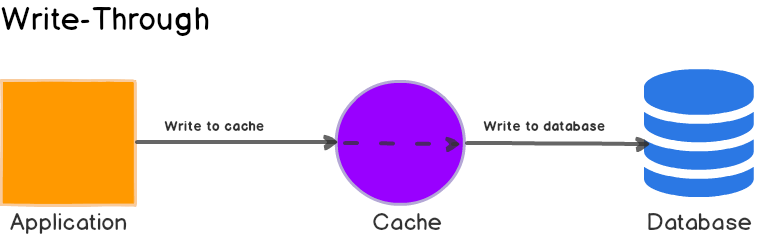
Write-through Cache Pattern
As with Read-through pattern, the application only interacts with the cache layer or server, but here the application writes data to the cache, and the cache is responsible for writing the data to the database synchronously.
Write-through increases the latency of write operations because the data must be written to the cache and then to the database. However, on the other hand, the cache will always be consistent with the database, no need to worry about implementing cache invalidation techniques.
Write-back (Write-behind) Cache Pattern
The pattern is similar to write-through, but the key difference is that writing the data to the database is done completely asynchronously through some jobs or message queues.
The Write-back pattern is used for write-intensive applications, because returning control to the caller happens immediately after writing data to cache results in low latency and high throughput.
Which cache eviction policy should be used?
The memory dedicated for cached data can fill up completely in the remote cache server or in the web service’s local memory, so there are several strategies, called cache eviction policies, to prevent out-of-memory problems. Typically the default cache eviction policy is LRU (Least Recently Used), which means that the least recently used items are discarded first.
However, LRU is not suitable for all possible cases. For example, some cache items may rarely be accessed, but they should not be automatically evicted from the cache because they can be costly to re-cache due to their size.
Here are some general cache eviction policies:
- Most Recently Used (MRU): The most recently used items are discarded first.
- Least Frequently Used (LFU): The least frequently used items are evicted from the cache, while the most used ones remain.
- Random Replacement (RR): The cache items are evicted randomly.
- No eviction: Cache items are never evicted from the cache.
Depending on the cache library or cache server, there may be various variations of the cache eviction policies above.
Conclusion
Implementing the cache is not a trivial task. Mistakes can be made at the design stage or at different stages of implementation. On the other hand, an implementation that was valid yesterday will not be valid today due to some changes in requirements or the introduction of new ones. Therefore, it is important to regularly check whether the current implementation meets the current business needs and, if necessary, make adjustments to the design as early as possible.


 Get Started with JavaScript Promises
Get Started with JavaScript Promises